Hi Dmitriy,
Let me explain the "stored on the chef server" part in a bit more detail.
When a CREATE or UPDATE request arrives at the chef server, the following
happens:
- the data is stored in PostgreSQL
- the data it sent to RabbitMQ to be asynchronously indexed
- a successful response is sent to the client
Asynchronously, chef-expander is pulling objects off the RabbitMQ queue IN
THE ORDER WHICH THEY WERE SAVED. We've taken great care to make
chef-expander run in parallel and preserve the save order of items that
arrive on the queue. Note: parallel is not necessarily "scaled across
multiple nodes".
If you have multiple RabbitMQ / chef-expander stacks, you introduce the
potential for the following type of data race:
t0. update request for databag_item DBI1 on erchef0
t1. update request for databag_item BDI1 on erchef1 (slightly different
data, last save "wins")
t2. erchef0 commits DBI1 to PostgreSQL
t3. erchef1 commits DBI1 to PostgreSQL
t4. erchef0 sends BDI1 to RabbitMQ0
t5. erchef1 sends DBI1 to RabbitMQ1
t6. chef-expander1 indexes DBI1 async
t7. chef-expander0 indexes DBI1 async
Note the ordering of t6 and t7. Once things are sent off into different
async queues, there is no guarantee that they will be indexed in the order
on which they were sent to the RabbitMQ queue.
It's also worth noting that even with a single RabbitMQ / chef-expander
stack you can still theorize a data race where the ordering of commits to
database differs from the ordering of commits to RabbitMQ. It's worth
keeping in mind that the chances of this contention occurring in the
RabbitMQ / chef-expander side of the transaction are much greater because
of the relative speed of the indexing operations. In a large Chef
infrastructure, Solr will spend a lot of time blocking update requests to
the index while it commits. The more time an item spends on the queue, the
higher the chance there is that something can get indexed out of order if
you're not careful.
You mentioned that you've been running fine with this setup for some time,
and I believe it. I've concocted quite a scenario above, and even conceded
that a single RabbitMQ / chef-expander is not guaranteed to prevent
out-of-order indexing. Historically, this was REAL problem with the Chef
Server. Older versions of the chef-client saved the node at the beginning
of the run without all of the attributes fully realized, and once again
saved the node at the end of the run. If the initial save of the client
data was the one that "won" the data race, in many cases you'd end up
having searches that failed because of attributes that you depended on not
being indexed. It was even worse when a chef-client run issued 3 saves, or
a recipe triggered a save.
If you find that a single RabbitMQ / chef-expander stack is not meeting
your needs for some reason, we should work together to improve the
horizontal scalability of the chef-expander.
On Tue, Apr 29, 2014 at 11:11 PM, DV vindimy@gmail.com wrote:
Hmm, Stephen, when you say "indexable objects are stored on chef server",
you mean there's a call that comes in to the API (say, create new node)
that goes to erchef, which goes to chef-expander and rabbitmq? In that
case, one chef-expander and rabbitmq per erchef are appropriate, it seems,
as long as each erchef talks to its own chef-expander and rabbitmq.
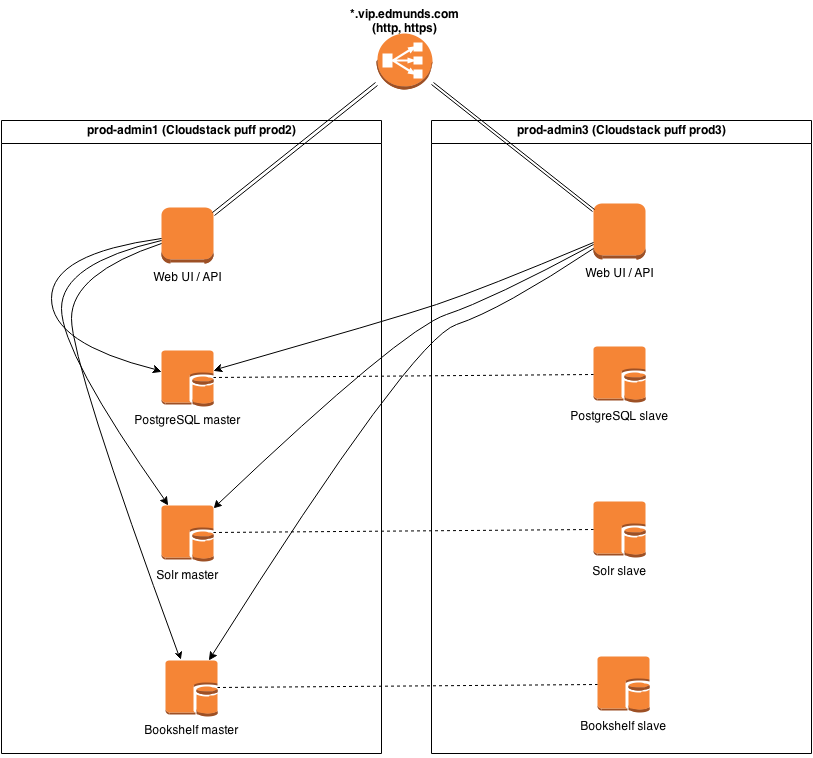
Here's how we've set up Chef 11 at my company:
Dropbox - chef11_layout.png - Simplify your life
The Web UI / API hosts have [chef-expander chef-server-webui erchef
rabbitmq nginx], Postgres/Bookshelf/Solr hosts are dedicated to their role.
Everything is set up with chef-server cookbook and custom roles, except
Postgres (since chef-server cookbook doesn't allow master/slave config).
Bookshelf is replicated on filesystem level (slave is read-only until
replication is broken).
We've ran this for a few months and haven't seen any issues yet.
On Thu, Apr 24, 2014 at 1:04 PM, Stephen Delano stephen@opscode.comwrote:
There should be some more crash logs from the console telling you what's
going on with erchef, but you're also going to have some other issues with
the setup you've described. If you're running enough erchef servers, you
might want to check that you're not exceeding the available connections of
the PostgreSQL server.
Multiple Bookshelfs:
Bookshelf was not designed to be run on multiple nodes. It has local
disk-based storage for the contents of your cookbooks.
Multiple Chef Expanders / RabbitMQ / Solr:
You also don't want to run multiple search stacks. When indexable objects
are stored on the chef server, their contents are shuffled off to a
RabbitMQ queue for which there is a chef-expander listener that's ready to
consume that data, "expand" it, and send it to Solr for indexing. First, if
you have multiple expanders as consumers to the rabbit queue, you're
introducing the chance that the data is indexed out-of-order. This problem
is exacerbated when you start to add multiple RabbitMQs (which erchef talk
to which queues) and multiple Solrs (which erchefs and expanders talk to
which Solr).
On Thu, Apr 24, 2014 at 9:42 AM, Darío Ezequiel Nievas <
dario.nievas@mercadolibre.com> wrote:
Hi Guys,
I'm having a bit of a problem trying to scale erchef between several
nodes
First, let me give you guys an overview of my environment
-2 (there will be more) servers behind a load balancer, running the
following services:
-bookshelf
-chef-expander
-chef-server-webui
-erchef
-nginx
-2 servers behind a load balancer, runing these services:
-chef-solr
-rabbitmq
-a Postgresql cluster (using pgpool) for the chefdb
Now, the problem
I can't seem to have erchef listening on port 8000 on both servers at
the same time. When erchef starts on one of the servers, it starts crashing
on the other one
=CRASH REPORT==== 24-Apr-2014::12:35:15 ===
crasher:
initial call: sqerl_client:init/1
pid: <0.131.0>
registered_name:
exception exit: {stop,timeout}
in function gen_server:init_it/6 (gen_server.erl, line 320)
ancestors: [<0.112.0>,pooler_pool_sup,pooler_sup,sqerl_sup,<0.107.0>]
messages:
links: [<0.112.0>]
dictionary:
trap_exit: false
status: running
heap_size: 4181
stack_size: 24
reductions: 22425
neighbours:
=SUPERVISOR REPORT==== 24-Apr-2014::12:35:15 ===
Supervisor: {<0.112.0>,pooler_pooled_worker_sup}
Context: child_terminated
Reason: {stop,timeout}
Offender: [{pid,<0.131.0>},
{name,sqerl_client},
{mfargs,{sqerl_client,start_link,undefined}},
{restart_type,temporary},
{shutdown,brutal_kill},
{child_type,worker}]
-If I stop erchef on node 1, the crash reports stop, and erchef starts
listening on node2:8000
-Then, If I try to start erchef on node1, It won't work, unless I stop
it on node2
Is there a way to avoid this, in order to be able to scale as many
erchef instances as needed?
Thanks in advance!
Dario Nievas (Snowie)
MercadoLibre Cloud Services
Arias 3751, Piso 7 (C1430CRG)
Ciudad de Buenos Aires - Argentina
Cel: +549(11) 11-6370-6406
Tel : +54(11) 4640-8443
--
Stephen Delano
Software Development Engineer
Opscode, Inc.
1008 Western Avenue
Suite 601
Seattle, WA 98104
--
Best regards, Dmitriy V.
--
Stephen Delano
Software Development Engineer
Opscode, Inc.
1008 Western Avenue
Suite 601
Seattle, WA 98104
{kind=link}